
移动云
围绕高性能云原生基础设施共建,聚焦超大规模集群的关键技术创新与工程落地,持续提升国产云基础设施的规模化能力与体系水平。
背景
随着云计算的深度普及与AI、大数据等业务爆发,云原生基础设施正从中小规模部署阶段,向超大规模生产级集群加速演进,然而业界普遍面临多项挑战:
- 面向海量容器与高并发负载,集群在调度、控制面与资源管理等关键技术点上面临规模瓶颈,如:
- Kubernetes在上万节点集群下出现API Server压力过大,不定时反复重启、ETCD响应延迟等问题。
- 大规模Pod调度时延增高,直接影响业务启动与资源利用效率。
- 随着集群规模扩大,单一技术优化难以支撑整体稳定性与效率,需要通过工程化体系建设,实现自动化运维等能力协同,如:
- 跨地域的资源编排和故障定位难度增加,统一监控与弹性管理成为痛点。
- 故障传播与快速恢复难,单节点与单服务异常可能波及整个集群。
- 计算、存储和网络资源存在碎片化和调度冲突问题,如何保证整体吞吐、资源利用率和任务性能成为关键问题。
针对这些挑战,移动云联合openFuyao打造面向超大规模场景的高性能、高可靠、可演进的云原生集群创新方案。
解决方案
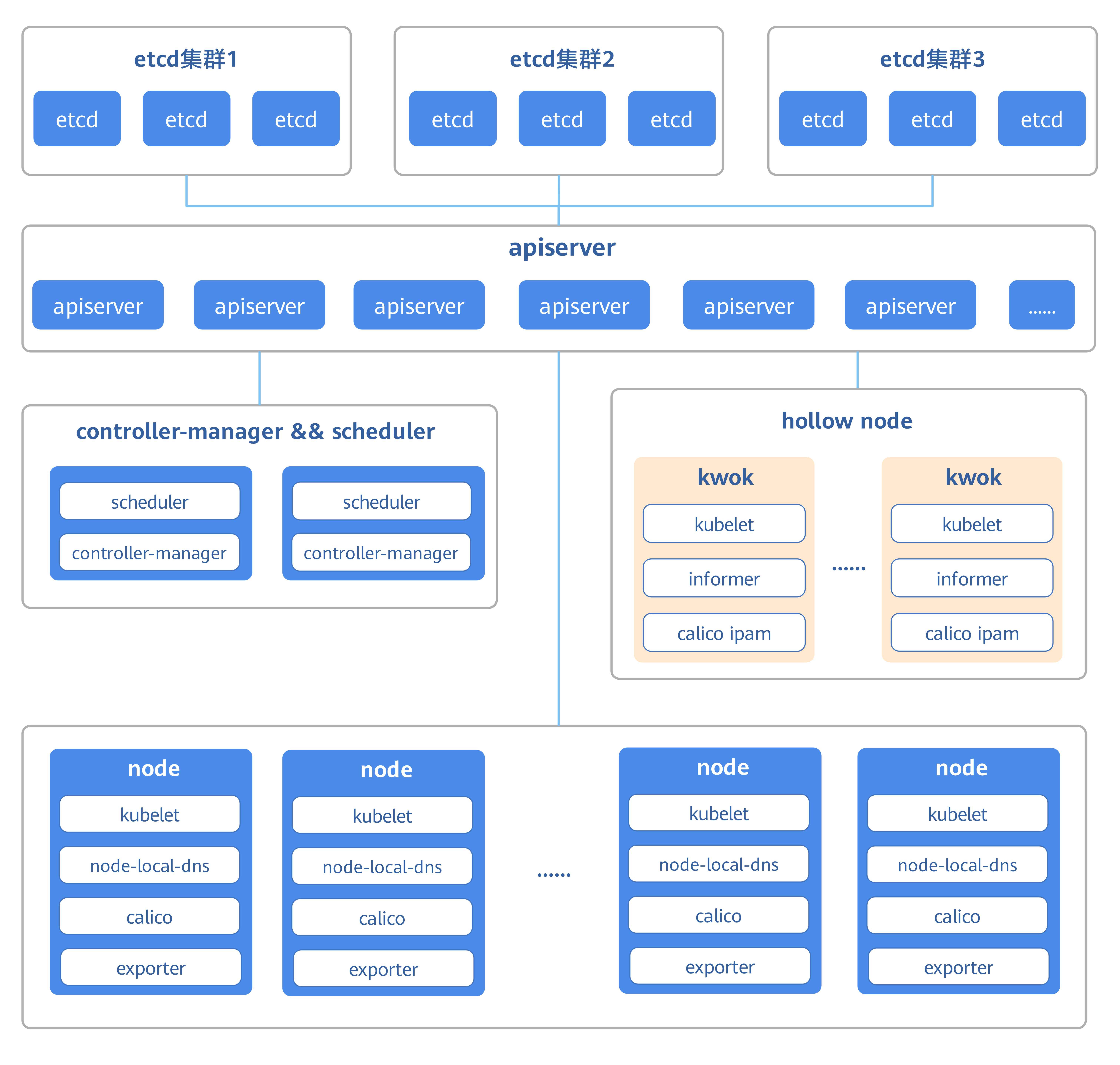
支撑单集群十万卡规模的稳定纳管,有效防御List-Watch请求风暴,成功抵御流量冲击引发的集群雪崩。
控制面架构优化:
- ETCD数据拆分和高可用设计:将ETCD拆分为三套独立集群,有效降低ETCD QPS,提升系统吞吐能力;并配置自动清理机制及时清除脏数据,进一步增强ETCD的可靠性。
- 核心组件和系统参数优化:将API Server扩展至9个实例,借助IPVS实现流量的均衡分发;同时针对List-Watch可能引发的流量风暴,通过APF机制进行针对性限流,避免集群整体过载,并调整goaway-chance参数,加速释放不稳定连接资源。
- 对controller-manager、scheduler、kubelet、kube-proxy、coredns等核心组件进行多维参数调优,优化资源利用与调度延迟。
批量调度与任务并发优化
- 支持批量数据传入与解析,减少接口调用次数。
- 基于PodGroup的一次性Filter与Score策略,大幅降低调度复杂度。
- 1.6万Pod创建与调度耗时由33分钟缩短至10分钟以内,显著提升任务启动效率。
监控体系升级:基于VictoriaMetric的高性能监控架构
- 高性能:计算存储分离架构,各组件均可水平扩展,轻松应对百万级指标写入与毫秒级查询。
- 低成本:远超Prometheus的压缩能力,显著降低存储成本70%+。
- 高可用:VM集群组件无单点故障,Kubernetes节点池隔离避免资源争抢,保障平台自身稳定性。
应用价值
- 支撑海量云原生业务规模化运行,满足容器、微服务和AI任务在高并发、高弹性场景下的稳定承载需求。
- 提升系统稳定性与可靠性,通过Kubernetes核心组件优化,降低大规模运行场景下的故障影响面。