
openFuyao技术讲堂 | 超大规模集群

 2026-05-15
2026-05-151. 特性介绍
超大规模集群项目致力于构建和优化面向AI训练与高性能计算(HPDA)的超大规模Kubernetes集群。核心目标是突破单集群纳管上限,通过系统性优化,稳定支撑1.6万节点的单集群,并为未来50万卡规模设计多集群协同架构。我们聚焦于解决超大规模场景下Kubernetes核心组件、调度、网络及可观测性的瓶颈问题,尤其针对昇腾等国产化算力的大规模集群管理进行了深度适配与优化。
1.1 应用场景
本特性专为突破传统单集群资源上限设计,核心服务于需要万节点级资源统一调度与协同的大规模计算场景。
| 应用场景 | 详情 |
|---|---|
| 万卡级AI训练 | 支撑数千至数万张昇腾NPU卡协同,满足万亿参数大模型等超大规模分布式训练需求 |
| 海量并行计算 | 适用于气候模拟、基因测序等需要数万计算核心并行的科学计算与批量处理任务 |
| 高并发推理服务 | 可弹性部署数十万个模型实例,承载互联网级AI服务的高并发推理请求 |
1.2 能力范围
本项目的优化与增强覆盖以下核心领域。
- Kubernetes控制面强化:针对kube-apiserver、etcd、kube-controller-manager等核心组件进行深度优化,保障控制面在超大规模下的稳定性与高性能。
- AI作业调度优化:集成并增强Volcano调度器,针对昇腾AI作业特点,提供批量创建、调度、绑定acJob pod能力。
- 高性能与可观测性网络:优化容器网络、服务发现(DNS)和网络策略,确保东西向流量高效、稳定;集成VictoriaMetrics,实现千万级时间序列数据的毫秒级采集与查询。
1.3 亮点特征
- 极致规模:单集群支持1.6万节点(128K卡),突破Kubernetes官方宣称的上限。
- 核心组件高可用:通过多实例负载均衡、读写分离、数据与事件分离等技术,确保kube-apiserver、etcd等关键组件无单点故障与性能瓶颈。
- 批量调度:提供组调度(PodGroup),完美适配AllReduce等分布式训练拓扑需求,提升大作业调度成功率与集群利用率。
- 毫秒级服务发现:通过DNS分级部署与本地缓存,将超大规模集群内服务解析从秒级优化至毫秒级。
- 全方位可观测:基于VictoriaMetrics,构建能够处理亿级监控指标的高性能监控体系,提供集群、节点、Pod、容器及NPU的立体化监控。
2. 实现原理
表1 超大规模集群部署与训练流程
| 阶段 | 关键动作 | 核心技术/工具 | 目标 |
|---|---|---|---|
| 1. 控制面高可用部署 | • kube-apiserver多实例 + VIP负载均衡 • 集群元数据拆分存储 | • 负载均衡器 (VIP) • etcd三集群 + 自动清理策略 | 建立稳定、高吞吐、低延迟的集群控制入口与数据存储层。 |
| 2. 大规模任务调度 | Volcano启用并行打分与二级队列调度 | Volcano Scheduler增强策略 | 实现秒级完成上万计算任务的排队与初始调度决策。 |
| 3. mind-cluster并发部署 | 主控节点通过Ansible并发SSH驱动 | Ansible批量运维 | 并发完成数百节点驱动、组件安装/升级,统一集群状态。 |
| 4. 任务提交与闭环 | 提交正式训练任务 | 标准K8s Job / Ascend Job | 集群自动完成调度 -> 建链 -> 训练 -> 监控的全闭环。 |
图1 超大规模集群优化技术全景
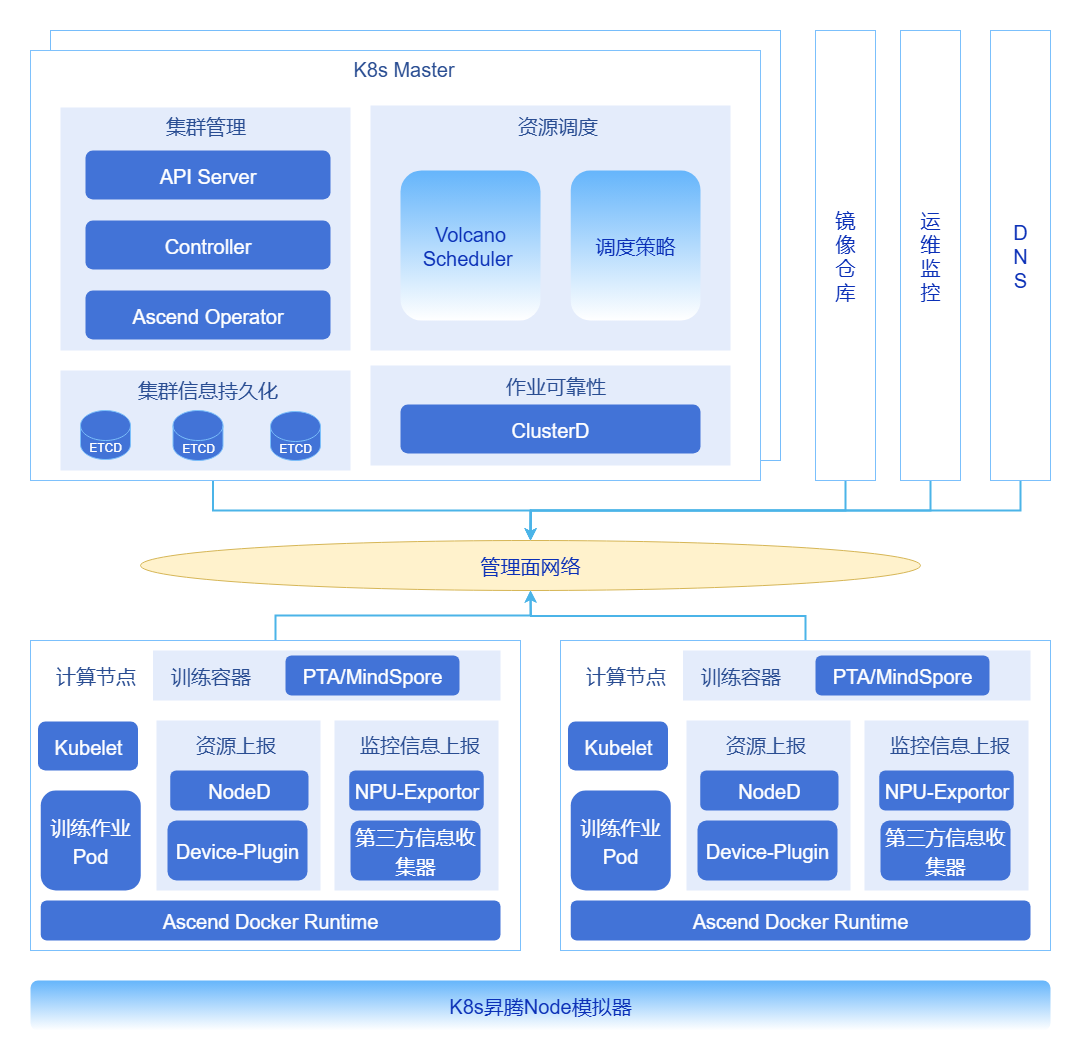
kube-apiserver负载均衡与流量优化
在大规模集群中,可通过部署多kube-apiserver实例,应对由大LIST请求导致的内存膨胀、长连接负载不均以及高负载下的响应延迟问题。
集群元数据拆分存储
针对因大规模Pod事件写入导致etcd QPS飙升、写入延迟增加并成为集群扩展瓶颈的情况,可采用物理分离的存储方案。通过部署独立的 "事件etcd集群"、"Pods etcd集群" 与"核心数据etcd集群",将Kubernetes核心元数据(如ConfigMap、Node、Service)、事件与租约(Events/Leases)以及Pod数据分别存入不同集群,有效消除相互干扰。同时实现etcd数据的自动压缩与碎片整理,定期清理历史与无效数据,控制数据增长以保持低延迟性能。
DNS分级部署
在拥有数万Pod的超大规模集群中,默认的CoreDNS会面临巨大的解析请求压力,导致响应时间可能达到秒级。为此,可构建分级DNS架构,通过在节点级别部署Local DNS来缓存记录,使CoreDNS作为中心权威服务器仅处理缓存未命中的请求。此架构将绝大多数解析请求消化在本地,从而将DNS解析延迟从秒级降至毫秒级。
Ascend Job批量调度
基于Volcano Scheduler,实现针对昇腾(Ascend)NPU算力的深度适配,通过组调度(Gang Scheduling)和批量创建绑定,达成1.6万Pod在3分钟内完成调度,从而保障分布式训练任务的高效执行。
3. 安装部署
部署流程分为两个核心阶段:构建稳定高效的Kubernetes基础集群,部署面向AI训练的增强软件栈,详情请参见: https://docs.openfuyao.cn/zh/docs/v26.03/user_guide/sig-large-scale-cluster/user_guide/large_scale_cluster.html#安装
4. 未来展望
未来超大规模集群将在以下方面进行规划: 1、基于bke部署工具构建超大规模集群自动化部署方案;部署k8s集群时支持自定义配置IPV4、IPV6双栈协议。 2、构建基于nginx的去中心化负载均衡方案。 3、根据真实落地场景持续提升集群稳定性。
5. 资源参考
关于超大规模集群场景下的应用,我们提供了一系列最佳实践供您参考: https://docs.openfuyao.cn/zh/docs/v26.03/user_guide/sig-large-scale-cluster/best_practice/best_practices_for_tuning_kube_apiserver_in_the_ultra_large_scale_cluster_scenario.html#最佳实践
更多openFuyao v26.03版本软件包可在如下地址下载: https://www.openfuyao.cn/zh/download/
本文由openFuyao社区首发,欢迎遵照CC-BY-SA 4.0协议规定转载。