
openFuyao使能灵衢超节点:让容器业务丝滑释放节点能力

 2026-06-08
2026-06-081. 摘要
在 AI 算力规模持续扩展的背景下,灵衢超节点(UB)通过共享内存、内存借用、URMA 高速通信等机制,重构了计算节点内外的数据交互范式。然而,K8s 原生资源模型仍以单节点为边界,缺乏对超节点总线架构及新型编程模型的原生支持,无法直接释放 UB 在性能与效率上的优势。
为此,openFuyao 在 K8s 体系内构建了面向超节点的系统级使能能力,涵盖设备接入、网络通信、存储与共享内存抽象,以及基于总线拓扑的调度增强等关键组件;通过扩展 Device Plugin、CNI、CSI 及调度框架,引入超节点资源建模与运行时适配机制,使容器业务能够极简、无缝地使用共享内存、内存借用与高速通信能力。
2. K8s生态对超节点支持存在GAP
灵衢超节点引入了 UB 内存池化、高速网络、DPU/SSD 池化等全新能力,但 K8s 原生生态在资源抽象和调度编排上存在明显 GAP,主要体现在:
2.1 硬件资源抽象与接入GAP
K8s 原生资源模型以节点为固定边界,与超节点的池化特性存在根本冲突:
- 内存池化:超节点支持邻居节点间内存动态借用,导致单节点可用容量随时变化,而 K8s 的 kubelet 和调度器均基于静态容量做决策,无法感知这种变化。
- 网络管理:超节点支持 URMA 语义的高速通信网络,但当前无 CNI 能力供给给容器业务使用,需要构建 URMA 网络的设备插件,管理分配 URMA 网卡设备。
- DPU 与 SSD 池化:DPU 物理拉远部署,SSD 纳入池化管理,均需通过专门的 Device Plugin 和 CSI 插件实现跨节点发现、分配与挂载,K8s 原生插件体系无法直接支持。
因此,必须针对 UB 硬件形态构建特有的 CSI、CNI 及 Device Plugin,并对 K8s 资源监控体系进行适配,才能将超节点资源纳入统一管理。
2.2 调度编排与资源优化GAP
即便完成硬件接入,K8s 原生调度器仍以单节点为调度粒度,缺乏超节点级的协同与优化能力,核心差距体现在四个方面:
静态资源 vs 动态池化
K8s 假设节点资源固定不变,资源不足时只能让 Pod 持续等待或触发驱逐。超节点支持邻居内存借用和节点级垂直扩缩容,可在资源紧张时临时扩展容量,避免业务中断。单节点调度 vs 拓扑感知
K8s 调度器无法感知超节点内部拓扑(如上下半柜、邻居节点)的性能差异。超节点需要将互补型负载(资源波动大与资源平稳型)部署为邻居以平衡内存借用压力,同时将高带宽需求业务部署在同一内存池内,降低访问延迟。故障重启 vs 无感迁移
面对硬件故障或资源压力,K8s 只能重新调度 Pod 导致业务中断。超节点支持毫秒级容器热迁移,可在业务无感知的情况下完成切换与恢复。固定预留 vs 弹性超分
K8s 按配置全额预留资源,利用率受限且易产生浪费。超节点支持按需预留和动态超分,结合历史负载建模自动调优,在保障稳定的前提下显著提升资源利用率。
3. openFuyao灵衢超节点使能方案
3.1 超节点URMA网络支持
openFuyao 对接 K8s 生态,提供超节点 URMA 网络设备对容器的供给能力。URMA 高性能网络设备支持超大带宽的通信,容器业务通过 URMA 网络设备进行通信,可大幅度提升容器间网络通信效率。
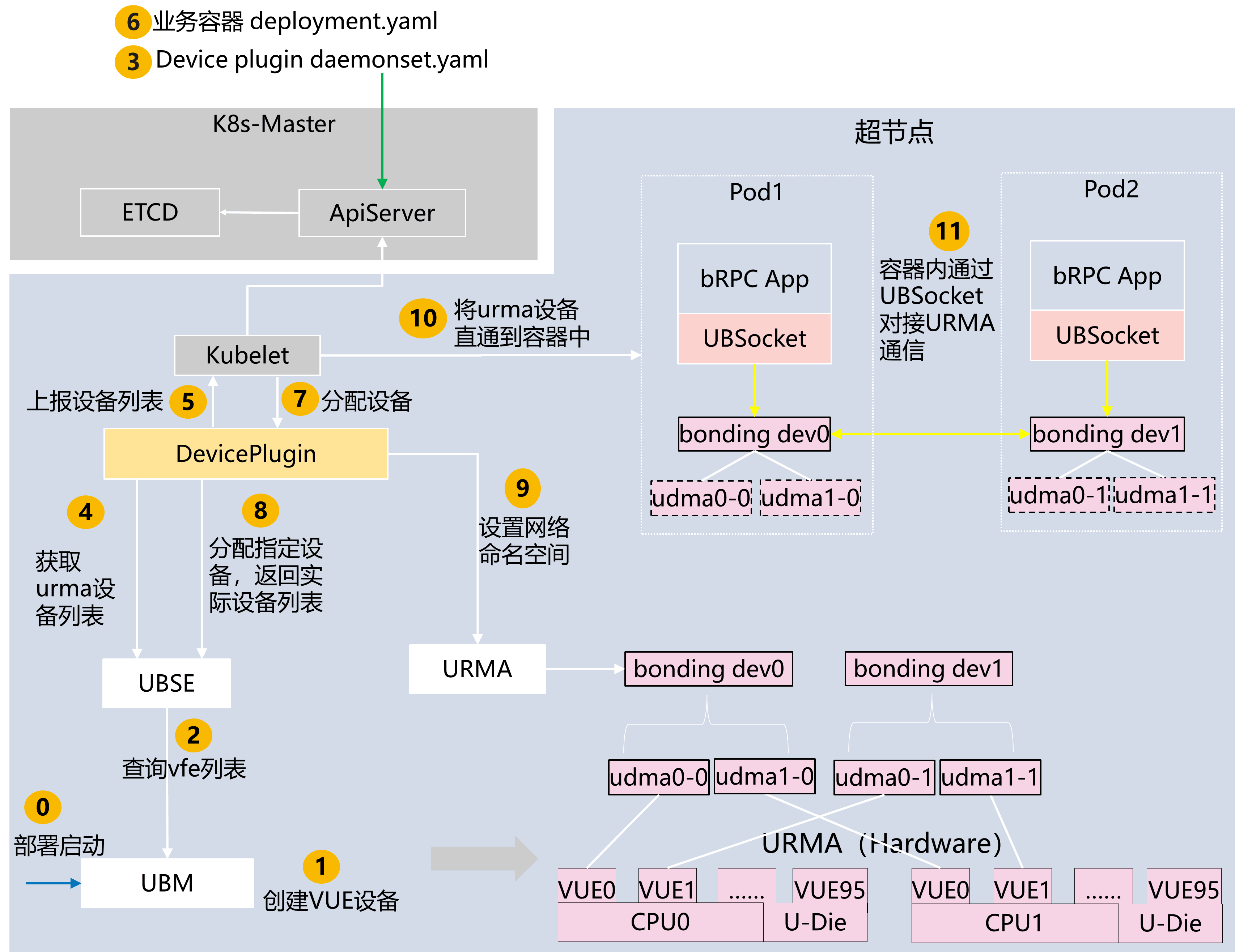
构建 URMA 网络设备插件,支持发现并上报节点中的 URMA 网络设备。在业务 Pod 申请使用时,分配指定设备相关列表,并通过 PreStartContainer 接口提前设置 URMA 网络设备的网络命名空间,将 URMA 设备供给容器,支持业务通过 UBSocket 进行高带宽、低时延的通信。
容器业务申请使用 URMA 网卡示例如下:
apiVersion: v1
kind: Pod
metadata:
name: demo
spec:
containers:
- name: demo
resources:
requests:
cpu: 500m
memory: 512Mi
unifiedbus.com/ub_net_device: 1
limits:
cpu: 1
memory: 1Gi
unifiedbus.com/ub_net_device: 13.2 超节点内存池化能力
openFuyao 对接 K8s 生态,提供集群级的内存池化与共享能力。其中,内存共享机制用于提升进程间的数据交互与通信效率,内存借用机制用于在集群范围内实现内存资源的动态调度与弹性复用,从而提高整体内存利用率并降低节点 OOM 风险。
3.2.1 内存无感借用
通过感知节点内存使用情况,基于内存逃生策略,触发内存借用,并使能容器内存冷热流动,提供基于借出状态和可用内存变化的调度能力,提升集群稳定性。
主要应用场景是当节点内存超分时,可以通过内存借用来扩容节点内存,当业务的短期峰值来临时,业务仍可正常运行,降低节点发生 OOM 的风险,且应用无感。matrixcontroller 负责根据各节点的资源使用情况来决策借用还是归还;matrixagent 负责节点资源使用情况的采集上报和决策的履行。
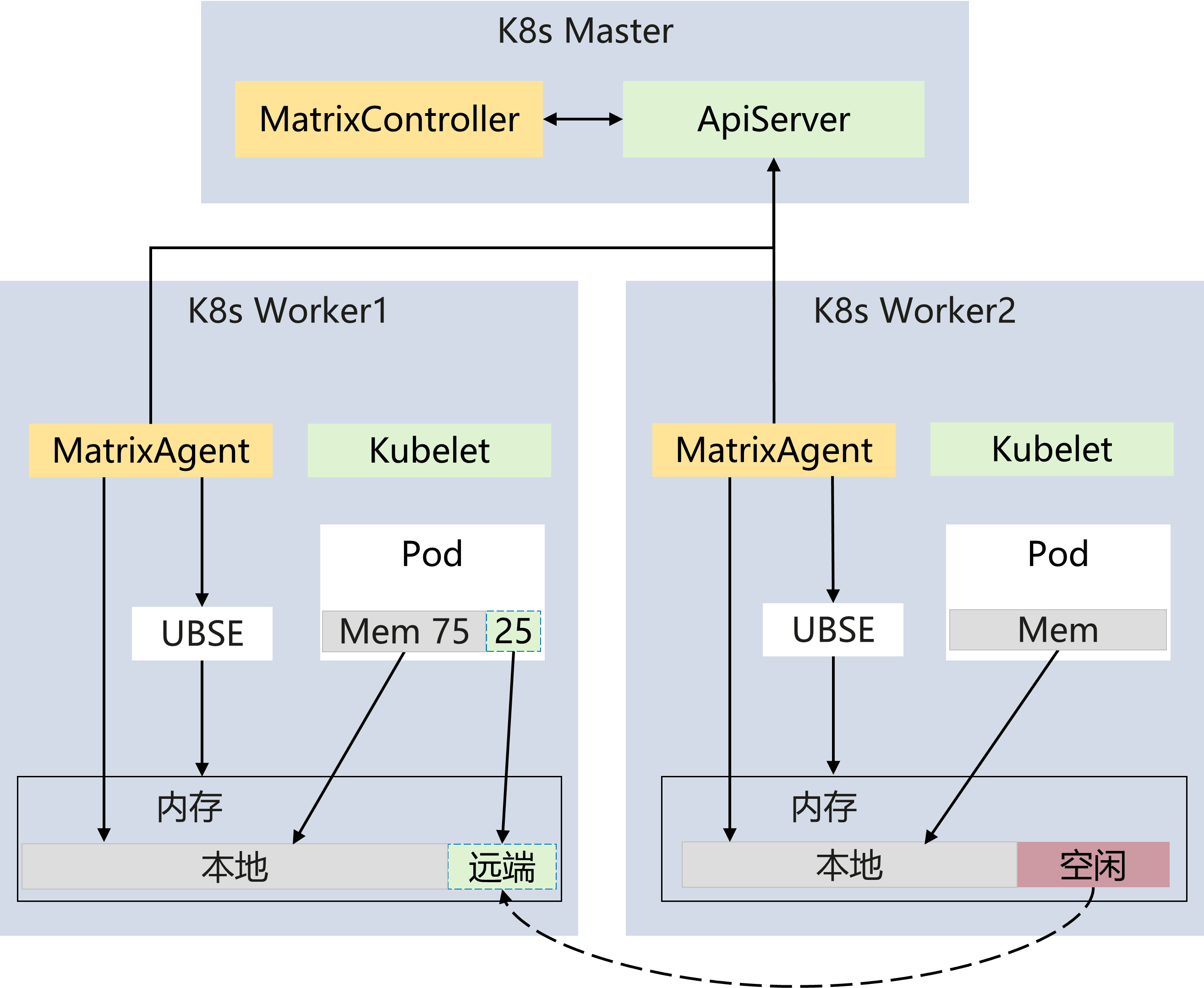
在使用时,首先需要配置水位线来告诉控制器借用和归还的条件,业务负载中需要新增标签来配置业务可以使用的远端内存的比例,业务使用的内存分配会变成 75% 的本地内存和 25% 的远端内存,25% 是目前的最佳实践,保证业务性能损耗小于 5%。
节点资源使用水线配置示例:
apiVersion: v1
kind: ConfigMap
metadata:
name: watermark-config
data:
returnLine : 80 # 归还水位线
secondLine: 90 # 内存借用水位线Pod 使用远端内存配置:
apiVersion: v1
kind: Pod
metadata:
name: demo
labels:
remote-mem-allocation-ratio: 25
spec:
containers:
- resources:
limits:
memory: 100Mi
cpu: 100m3.2.2 内存共享
共享是指将一块物理内存映射给多个业务,让业务可以进行数据的读写,来达到数据传输的目的。共享内存以设备的形式呈现,按需创建,通过标准的 CSI 的能力,将共享内存设备以卷的方式挂载给业务 Pod,方便业务进行读写访问;此外还代理了共享内存的管理接口,做容量限制,保证可靠性的同时,也使得业务代码在虚机和容器场景保持一致,减少业务适配点。
常见的使用场景如大数据等业务间需要交换大量数据,走传统的网络数据搬迁效率较低,可以通过共享内存交换数据,提升业务通信效率。
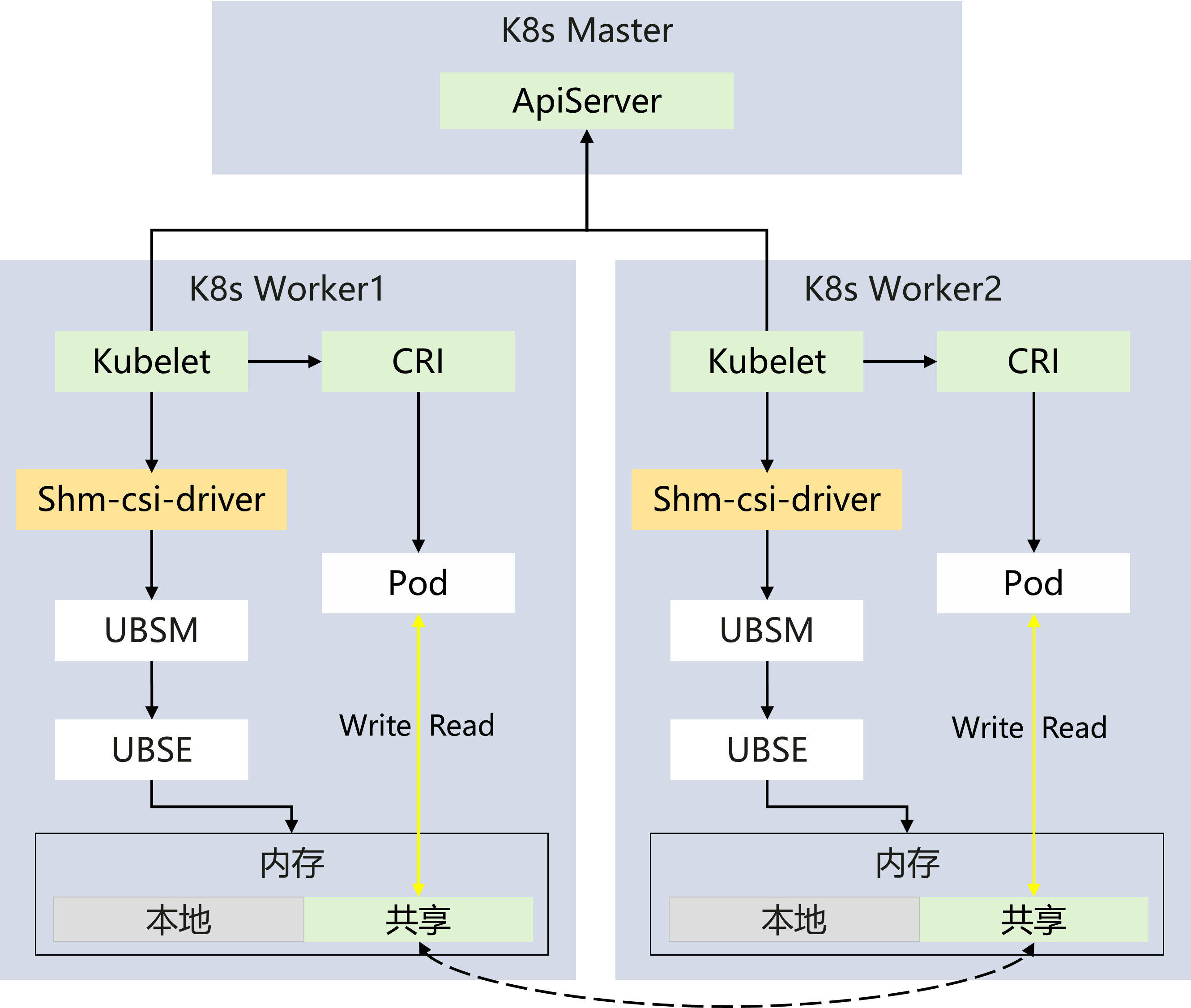
在使用时,首先我们需要创建一个共享内存声明,在负载中以卷的方式将共享内存设备挂载到设备目录下,业务就可以进行共享内存的读写来进行数据交换。
共享内存的声明与引用示例:
apiVersion: resource.ubsvirt.huawei.com/v1
kind: ShareMemoryVolume
metadata:
name: my-sharememory
namespace: kube-system
spec:
storage: 5Gi # 限额
---
containers:
- volumeMounts:
- name: my-volume
mountPath: /dev
volumes:
- name: my-volume
csi:
driver: shm-csi-driver
volumeAttributes:
type: matrixShareMem
identity: my-sharememory本文由openFuyao社区首发,欢迎遵照CC-BY-SA 4.0协议规定转载。