
InferNex:云原生分布式 LLM 推理加速套件——从生产痛点到算力的极致释放

 2026-06-09
2026-06-09王清珺,openFuyao 社区 AI Inference SIG Maintainer,深耕云原生分布式推理、软硬协同优化与昇腾/+鲲鹏算力生态,主导 InferNex 推理加速平台的设计与开源。
摘要
大模型推理正从“单卡部署”迈向“百卡集群服务”,但超长上下文 TTFT 延迟高达十秒级、异构算力利用率不足 50%、集群单点故障恢复分钟级三大痛点制约规模化落地。InferNex 是 openFuyao 社区首个面向昇腾 NPU + 灵衢总线(华为自研高速互联总线,支持统一编址和零拷贝内存语义访问)的云原生分布式 LLM 推理加速平台,以智能路由、计算-显存解耦、分布式多级缓存、近实时可观测四大引擎直击痛点——在前缀一致率 70% 场景下实现 TTFT 降低 43%、吞吐提升 50%、故障零损耗切流 <10s,在昇腾硬件感知调度和灵衢总线零拷贝直访上构建了 llm-d、NVIDIA Dynamo 均未覆盖的技术优势。
一、痛点驱动的核心特性
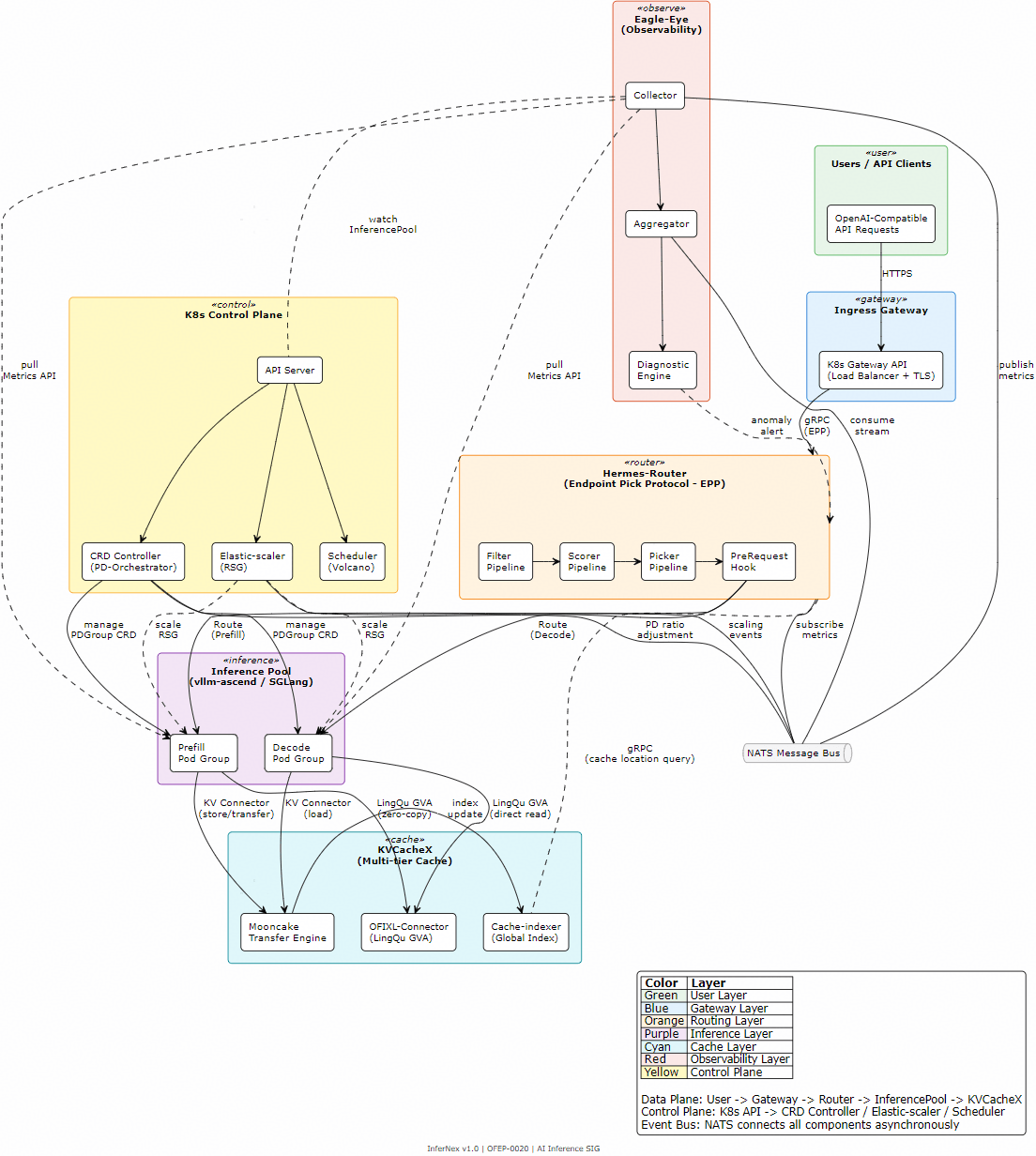
InferNex全景架构
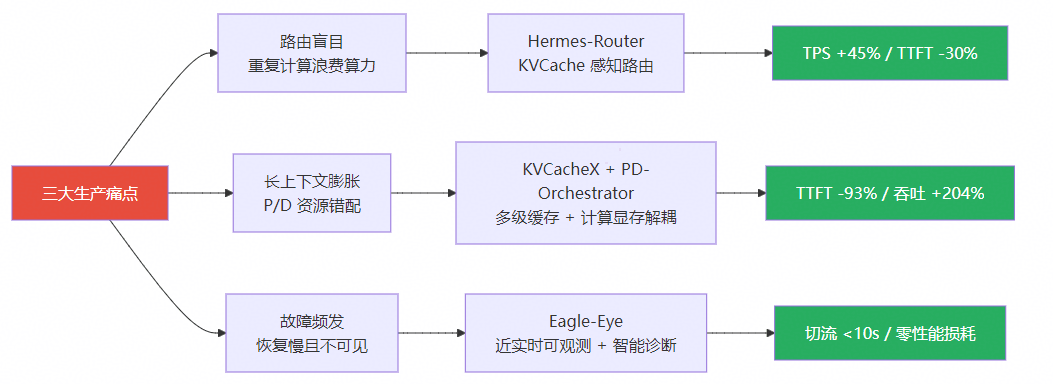
痛点一:路由盲目,重复计算浪费算力
场景:RAG/Agent 应用中,大量请求共享 system prompt 或长文档前缀。传统 Round Robin 轮询无视 KVCache 分布,每次请求都重新计算已缓存的前缀。在 90% 前缀命中场景下,理论上可造成超过 30% 的无效算力浪费。
解决——Hermes-Router 多因素智能路由:
基于 Kubernetes Gateway API Inference Extension (GIE) 框架构建四级流水线路由架构(Filter → Scorer → Picker → PreRequest Hook),实现三个维度的协同感知:
- KVCache 感知:查询全局 Cache-indexer 前缀命中信息,将请求路由到缓存命中率最高的 Prefill 实例,避免重复预填充
- 算力拓扑感知:感知昇腾 910B/910C HCCS 互联拓扑与 NPU 实时负载,实现异构算力等效调度
- 容灾切流:协同 Eagle-Eye 亚健康检测,预防性自动切流,故障切换零性能损耗
实测数据(v25.09,昇腾 910B4 集群,前缀一致率 70%):
| 前缀命中率 | TPS 提升 | TTFT 改善 |
|---|---|---|
| 30% | +1% | 基线持平 |
| 90% | +45% | -30% |
v26.03 集成测试进一步验证:智能路由 + 容灾场景下,P99 TTFT 降低 2.9%,P99 E2EL 降低 3.5%,且容灾切流过程零性能中断。
痛点二:长上下文膨胀 + Prefill/Decode 资源错配
场景:企业级 RAG 应用常需 32K-128K 上下文,KVCache 显存随上下文线性增长(以 Llama2-7B 为例,4K 上下文即占用约 2GB 显存)。同时 Prefill(计算密集)和 Decode(显存带宽密集)资源需求截然不同,固定配比导致算力浪费。
解决——KVCacheX 分布式多级缓存 + PD-Orchestrator 计算显存解耦:
KVCacheX 基于 Mooncake 构建四级缓存层次,将 KVCache 从单卡 HBM 释放到集群级共享资源池:
核心能力:
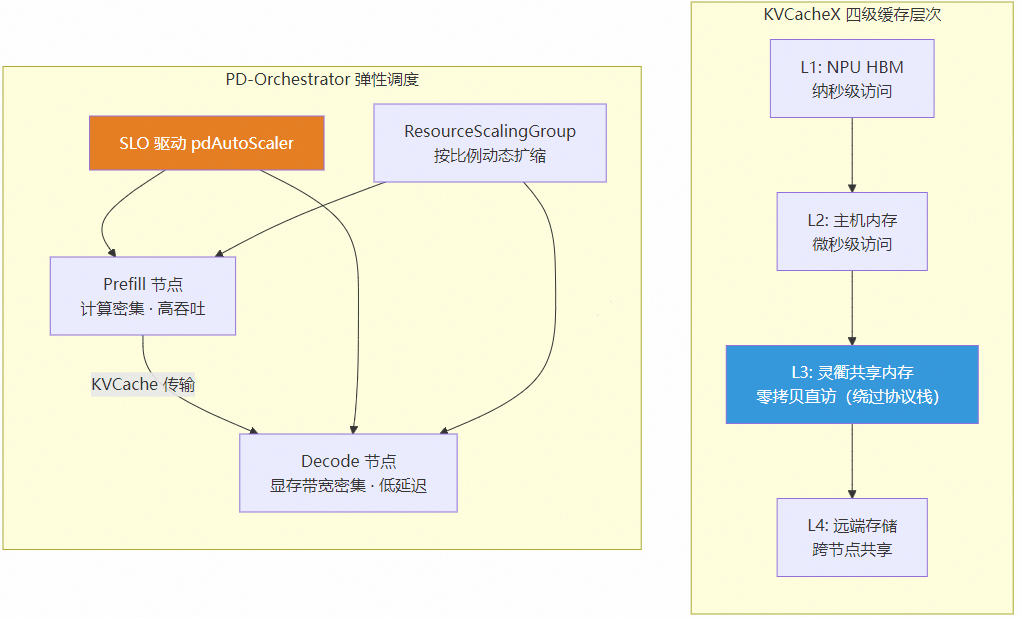
- 热点缓存加速:跨节点 KVCache 热点本地缓存,接口延迟降低 64-76%
- 灵衢总线直访:OFIXL-Connector 利用灵衢统一编址能力,绕过 TCP/RDMA 协议栈,零拷贝 KVCache 直访
- 全局索引:Cache-indexer 维护集群级 KVCache 位置元数据,支持跨节点可见与调度
PD-Orchestrator 实现计算-显存解耦与弹性伸缩:
- P/D 分离部署:P 节点专注高吞吐预填充,D 节点专注低延迟解码,独立扩缩容
- SLO 驱动弹性:基于 Eagle-Eye 秒级指标,pdAutoScaler 自动调整 P/D 配比
- 潮汐混部:白天推理、夜间训练,提升集群综合利用率
- 动态 PD 组扩缩容:ResourceScalingGroup(RSG)抽象资源管理,按比例动态 PD 扩缩
痛点三:百卡集群故障频发,恢复慢且不可见
场景:百卡级推理集群中硬件故障率显著上升,大 EP 场景下单节点故障可导致整个 EP 组不可用。传统方案依赖被动故障检测,恢复时间分钟级,严重影响 SLO。
解决——Eagle-Eye 近实时可观测与智能诊断:
基于 NATS 分布式消息队列实现秒级指标推送,构建“采集-诊断-决策-执行”闭环:
- 业务运行态:吞吐率、TTFT/TPOT 延迟分位数、KVCache 命中率
- 系统运行态:Pod 资源利用率、调度事件、弹性伸缩决策链路
- 硬件健康:NPU 温度/功耗/错误码、灵衢总线互联内存管理状态
- 智能诊断引擎:阈值规则 + 异常模式识别 → 故障定界结论与处置建议
关键指标:亚健康检测 → 预防性切流 <10s,零性能损耗。
二、竞争优势:对标 llm-d 与 NVIDIA Dynamo
2.1 差异化能力矩阵
| 能力维度 | InferNex (openFuyao) | llm-d (CNCF) | Dynamo (NVIDIA) |
|---|---|---|---|
| KVCache 感知路由 | ✅ 多因素协同(缓存+算力+负载) | ✅ 基础缓存路由 | ✅ 智能路由 |
| 硬件拓扑感知 | ✅ 昇腾 HCCS/灵衢互联拓扑 | ❌ 主要面向 GPU | ❌ 主要面向 GPU |
| 分布式 KVCache | ✅ Mooncake + 灵衢零拷贝直访 | ✅ KV Cache Manager | ✅ NIXL 传输 |
| 高速互联适配 | ✅ 灵衢统一编址内存语义共享 | ❌ | NVLink/NVSwitch |
| PD 分离调度 | ✅ SLO 驱动动态配比 | ✅ 基础分离 | ✅ Disaggregated |
| 弹性伸缩 | ✅ <90s 含权重加载 + RSG 整组扩缩 | ✅ K8s HPA | ✅ 基础 scaling |
| 亚健康检测与预防性切流 | ✅ Eagle-Eye 零损耗 | ❌ | ❌ |
| 多引擎兼容 | ✅ vLLM/SGLang/TensorRT-LLM | ✅ vLLM | ✅ TRT-LLM |
| 开源生态 | ✅ 完全开源(组件可选装、可解耦) | ✅ CNCF 沙箱 | ⚠️ 核心调度闭源 |
2.2 三个维度的技术领先性
维度一:软硬协同深度——昇腾差异化的技术锚点
llm-d 和 Dynamo 均围绕 NVIDIA GPU 生态构建,调度策略与硬件拓扑解耦。InferNex 独有昇腾 NPU HCCS 互联感知 + 灵衢总线统一编址能力,在分布式 KVCache 传输场景实现零拷贝直访,绕过 TCP/RDMA 协议栈开销。这不是简单的硬件适配,而是将硬件互连特性深度融入调度决策——业界尚无多样化算力亲和的同类方案。
维度二:从被动容错到预防性容灾
百卡级推理集群中,硬件亚健康(过热、ECC 错误率上升)往往先于完全故障出现。InferNex 通过 Eagle-Eye 亚健康检测(过载降频、NPU 错误码)驱动预防性切流,在故障发生前完成流量迁移,实现 <10s 切流、零性能损耗。
维度三:全栈开源与组件解耦
NVIDIA Dynamo 核心调度组件未完全开源,部分关键能力仍绑定 NVIDIA 硬件生态。InferNex 组件全部开源(Hermes-Router、KVCacheX、Eagle-Eye、PD-Orchestrator、Elastic-Scaler),采用 K8s 原生 CRD + Helm Chart 架构,用户可自由组合和替换任何组件——这正是开源项目应有的形态:组件可选装、可解耦,避免供应商锁定。
2.3 未来技术竞争力空间
InferNex 正在布局的技术方向将进一步拉开差距:
- DSA/HA 稀疏注意力 KVCache 管理:面向 MoE、长上下文场景的稀疏 KV 数据布局与选择性驻留,业界尚无成熟方案
- 灵衢 P2P 多播权重分发:利用灵衢总线 P2P 能力实现模型权重并行分发,弹性伸缩提速 3x+
- 跨集群联邦推理调度:基于 Karmada 的跨集群分布式推理作业分发与资源编排
- 智能缓存预热:基于请求访问模式画像的预测性 KVCache 预搬移,请求到达前热点数据已就位
三、快速上手:5 分钟部署 InferNex 推理集群
InferNex 通过 Helm Chart 提供一键式集成部署,下面以昇腾 910B 集群上的 Qwen3-8B PD 分离推理场景为例,展示从零开始的完整流程。
3.1 环境准备
硬件要求:
- 每个推理节点至少一张昇腾 910B4 NPU
- 每节点至少 32GB 内存、4 CPU 核
- 节点间 RoCE 网络互通(200GE+)
软件要求:
- Kubernetes v1.33.0+
- 已安装 npu-operator(昇腾设备插件)
- Helm 3.x
- 在线安装需能访问 oci://cr.openfuyao.cn 镜像仓库
3.2 一键部署
InferNex 提供三种部署方式,按需选择:
方式一:OCI 镜像仓库(推荐在线环境)
helm pull oci://cr.openfuyao.cn/charts/infernex --version 0.21.1
tar -xzvf infernex-0.21.1.tgz
helm install -n ai-inference infernex ./infernex方式二:GitCode 源码构建
git clone https://gitcode.com/openFuyao/InferNex.git
cd InferNex/charts/infernex
helm dependency build
helm install -n ai-inference infernex .方式三:离线部署(适用于隔离网络环境)
wget https://openfuyao.obs.cn-north-4.myhuaweicloud.com/openFuyao/ext-components/InferNex/openFuyao-infernex-offline-v26.03.tar.gz
tar -xzvf openFuyao-infernex-offline-v26.03.tar.gz
cd openFuyao-infernex-offline-v26.03 && bash install.sh
helm install -n ai-inference infernex ./infernex参考文献
[1] openFuyao AI Inference SIG. InferNex 技术专家技术规划报告. sig-ai-inference/docs/plans/2026-03-31-infernex-technical-roadmap-design.md
[2] AI Inference SIG. AI推理优化性能测试报告 v25.09 — Hermes-Router KVCache-aware 路由策略基准测试. sig-ai-inference/reports/performance/
[3] AI Inference SIG. Mooncake Store 热点缓存性能测试报告 v25.12 — 端到端 LLM 服务 TTFT/吞吐提升验证. sig-ai-inference/reports/performance/
[4] AI Inference SIG. v26.03 AI推理集成部署特性性能基线对比测试报告 — 智能路由容灾与弹性伸缩验证. sig-ai-inference/reports/performance/v26.03/
[5] openFuyao AI Inference SIG. InferNex 系统全景架构图 (OFEP-0020). sig-ai-inference/images/2026-05-12-ofep0020-architecture/
[6] openFuyao. AI推理集成部署用户指南. InferNex docs
[7] llm-d Project. llm-d: High-performance distributed inference on Kubernetes. github.com/llm-d/llm-d
[8] NVIDIA. NVIDIA Dynamo: High-throughput inference serving. github.com/ai-dynamo/dynamo
[9] Mooncake. kvcache-ai/Mooncake: A KVCache-centric disaggregated architecture for LLM serving. github.com/kvcache-ai/Mooncake
[10] vLLM Project. vLLM: High-throughput and memory-efficient LLM serving. github.com/vllm-project/vllm
[11] Kubernetes Gateway API Inference Extension. kubernetes-sigs/gateway-api-inference-extension
本文由openFuyao社区首发,欢迎遵照CC-BY-SA 4.0协议规定转载。